LDL Health Plan - Single Documentation
Dark mode doc with setup, architecture, important code, and screenshot gallery (1.jpeg to 13.jpeg) in one HTML file.
1) How to Start Project
Backend
cd "c:\Reaserch\RP 47"
python -m venv venv
venv\Scripts\activate
pip install -r backend\requirements.txt
uvicorn backend.main:app --reload --host 0.0.0.0 --port 8000Frontend (Expo)
npm install
npm startSet backend URL in .env: EXPO_PUBLIC_API_URL=http://YOUR_IP:8000
2) How LLM Is Trained
- Chatbot training script:
train_chatbot_ldl.py - Base model:
HuggingFaceTB/SmolLM2-360M-Instruct - Method: LoRA/PEFT adapter saved at
smol-360m-ldl-guide - Guideline + Chat endpoints both use this adapter
3) File Connections
| Part | Connected To |
|---|---|
| App API calls | utils/api.js -> constants/api.js -> backend endpoints |
| Backend routes | backend/main.py -> backend/predict.py and backend/llm.py |
| Guideline state | context/GuidelineContext.js -> all plan/reminder/motivational screens |
| LLM runtime | backend/llm.py loads adapter from smol-360m-ldl-guide |
4) File Structure
RP 47/
|- App.js
|- constants/api.js
|- utils/api.js
|- context/GuidelineContext.js
|- navigation/MainTabs.js
|- screens/...
|- backend/main.py
|- backend/predict.py
|- backend/llm.py
|- ml/output/ldl_risk_model.joblib
|- train_chatbot_ldl.py
|- smol-360m-ldl-guide/
|- assets/
|- doc/index.html5) Assets + Doc Paths
App assets: c:\Reaserch\RP 47\assets\
This documentation: c:\Reaserch\RP 47\doc\index.html
Requested screenshot files: c:\Reaserch\RP 47\doc\1.jpeg ... c:\Reaserch\RP 47\doc\13.jpeg
6) Screenshots (One by One) – Application flow
These 13 screenshots are saved in doc/1.jpeg … doc/13.jpeg. Each one corresponds to a specific screen or state in the LDL app.
1. Mostly Impacted Lifestyle Factors
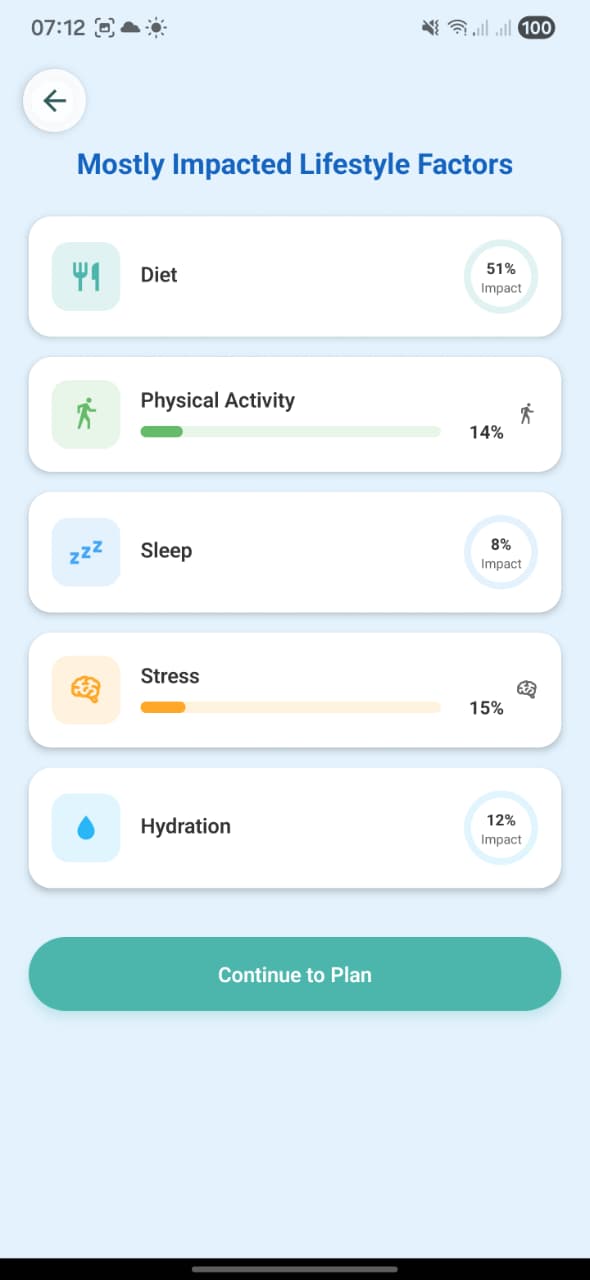
Screen: MostlyImpactedFactorsScreen. Shows the impact breakdown from the Random Forest model: Diet, Physical Activity, Sleep, Stress, Hydration with exact percentages (e.g. Diet 51%). User taps “Continue to Plan” to move to the LDL Reduction Plan and guideline generation.
2. Your LDL Reduction Plan (risk result)
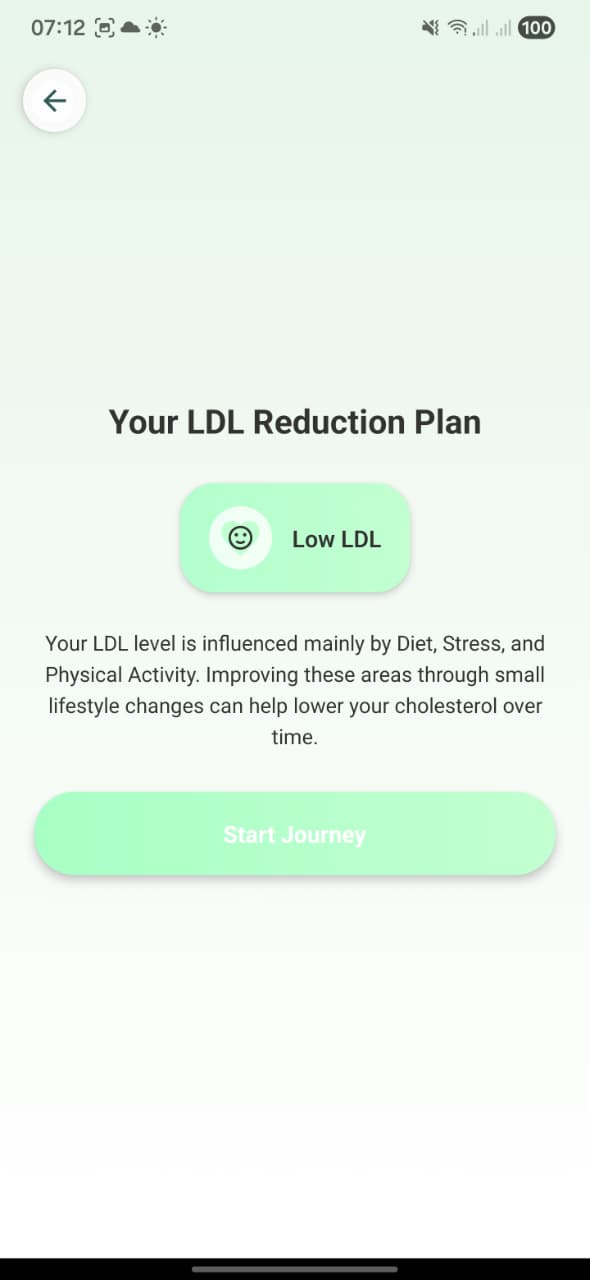
Screen: LDL result screen (“Your LDL Reduction Plan”). Displays the risk badge (e.g. Low LDL) and text explaining that LDL is influenced mainly by Diet, Stress, Physical Activity. The “Start Journey” button is what triggers fetching the AI guideline via POST /guideline.
3. Month 3 – Weekly Plan
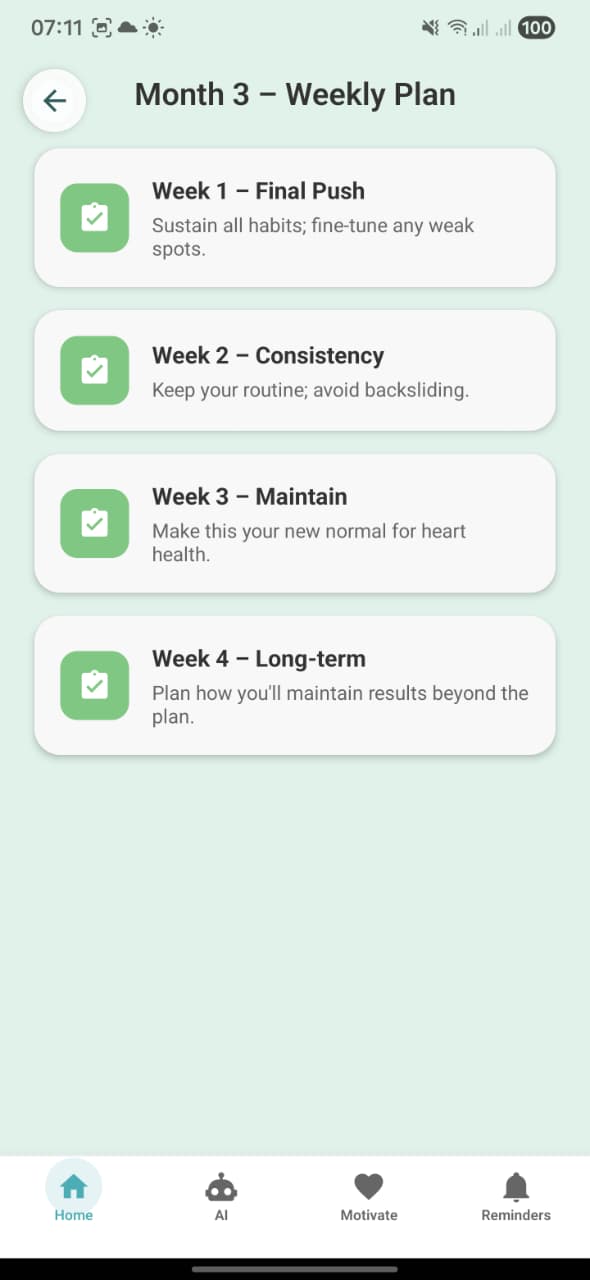
Screen: MonthPlanScreen in weekly mode. For Month 3, shows four weeks (Final Push, Consistency, Maintain, Long‑term) with short descriptions like “Sustain all habits; fine‑tune any weak spots.”
4. Month 3 – Daily Lifestyle Plan
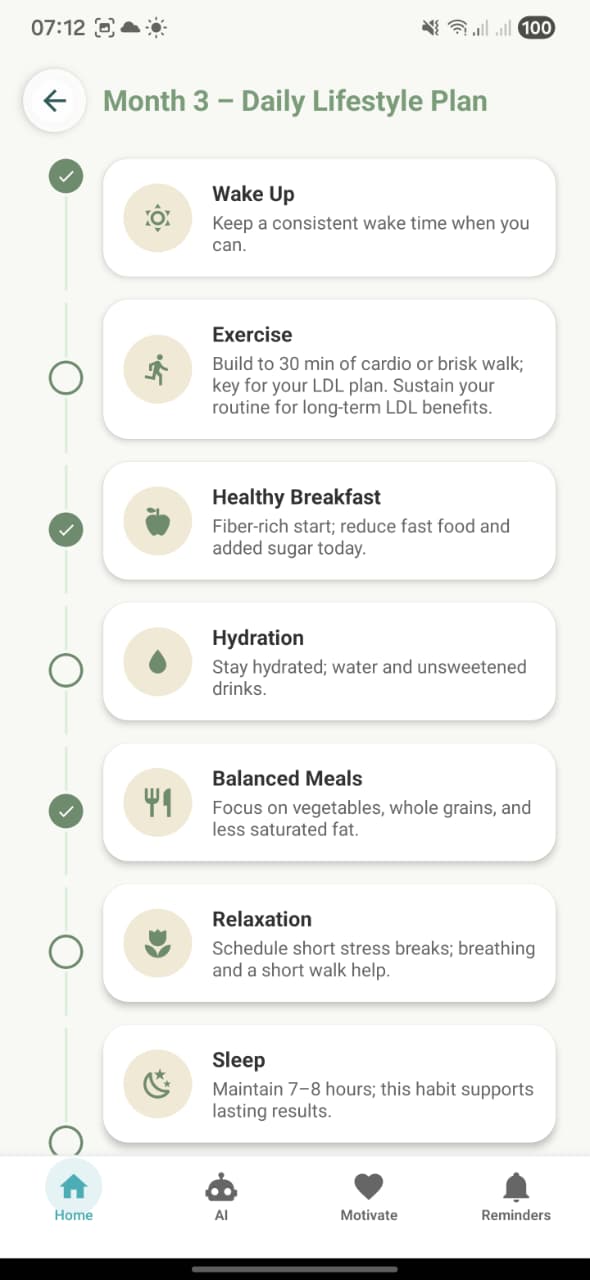
Screen: DailyPlanScreen for Month 3. Timeline of specific daily habits: Wake Up, Exercise, Healthy Breakfast, Hydration, Balanced Meals, Relaxation, Sleep, each with one‑line LDL‑focused guidance.
5. Motivational screen (Low LDL)
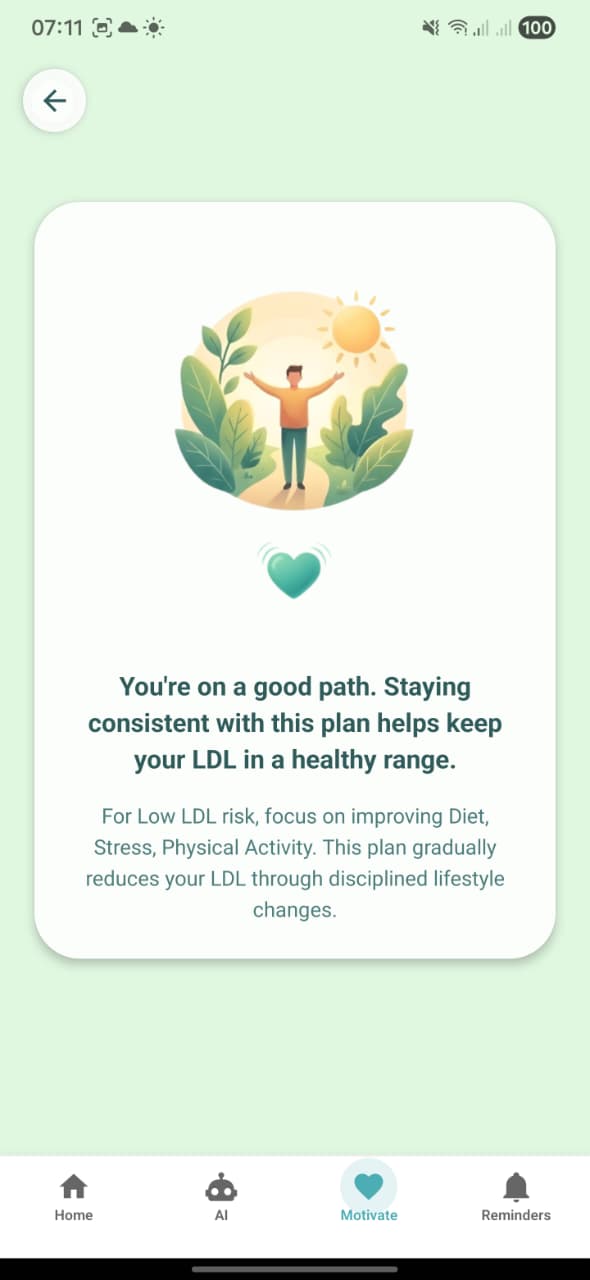
Screen: MotivationalScreen (Motivate tab). Card that says “You’re on a good path. Staying consistent with this plan helps keep your LDL in a healthy range.” with extra text about focusing on Diet, Stress, Physical Activity for low LDL.
6. Daily Reminders
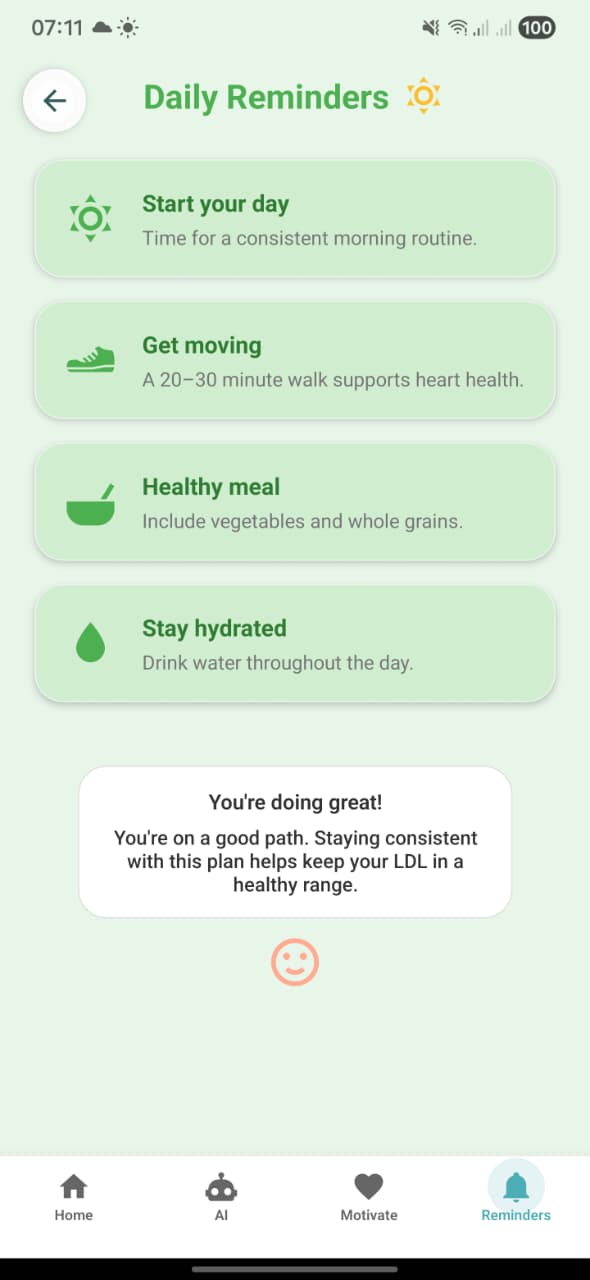
Screen: DailyRemindersScreen (Reminders tab). Shows reminders: Start your day, Get moving, Healthy meal, Stay hydrated, plus the centered affirmation bubble (“You’re doing great! … staying consistent with this plan helps keep your LDL in a healthy range.”).
7. AI Assistant conversation
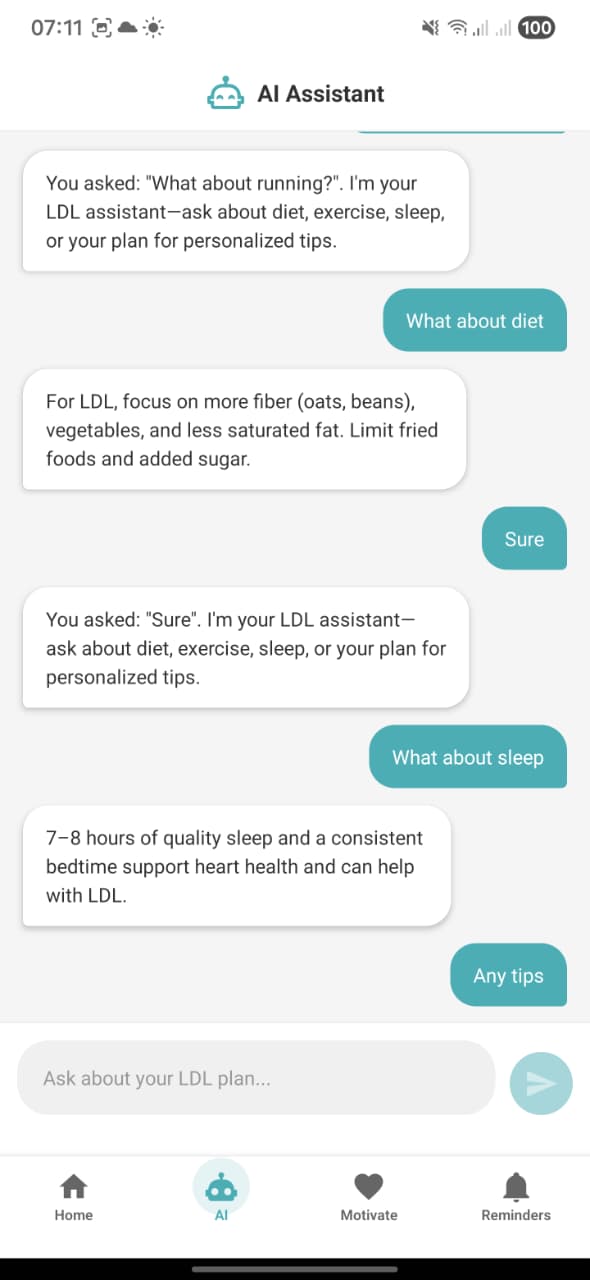
Screen: AiChatScreen. Conversation where user asks about running, diet, sleep, tips. Assistant replies with LDL‑specific advice (oats/beans, vegetables, less saturated fat; 7–8 hours of sleep; etc.), powered by /chat and the smol-360m-ldl-guide adapter.
8. Personalized Treatment Guideline Generator intro

Screen: Intro/splash screen with a person walking between a heart (LDL/HDL) and an AI brain, captioned “Personalized Treatment Guideline Generator – Your lifestyle‑based path to healthier cholesterol”. This is the high‑level AI guideline entry screen.
9. Lifestyle form – generating prediction
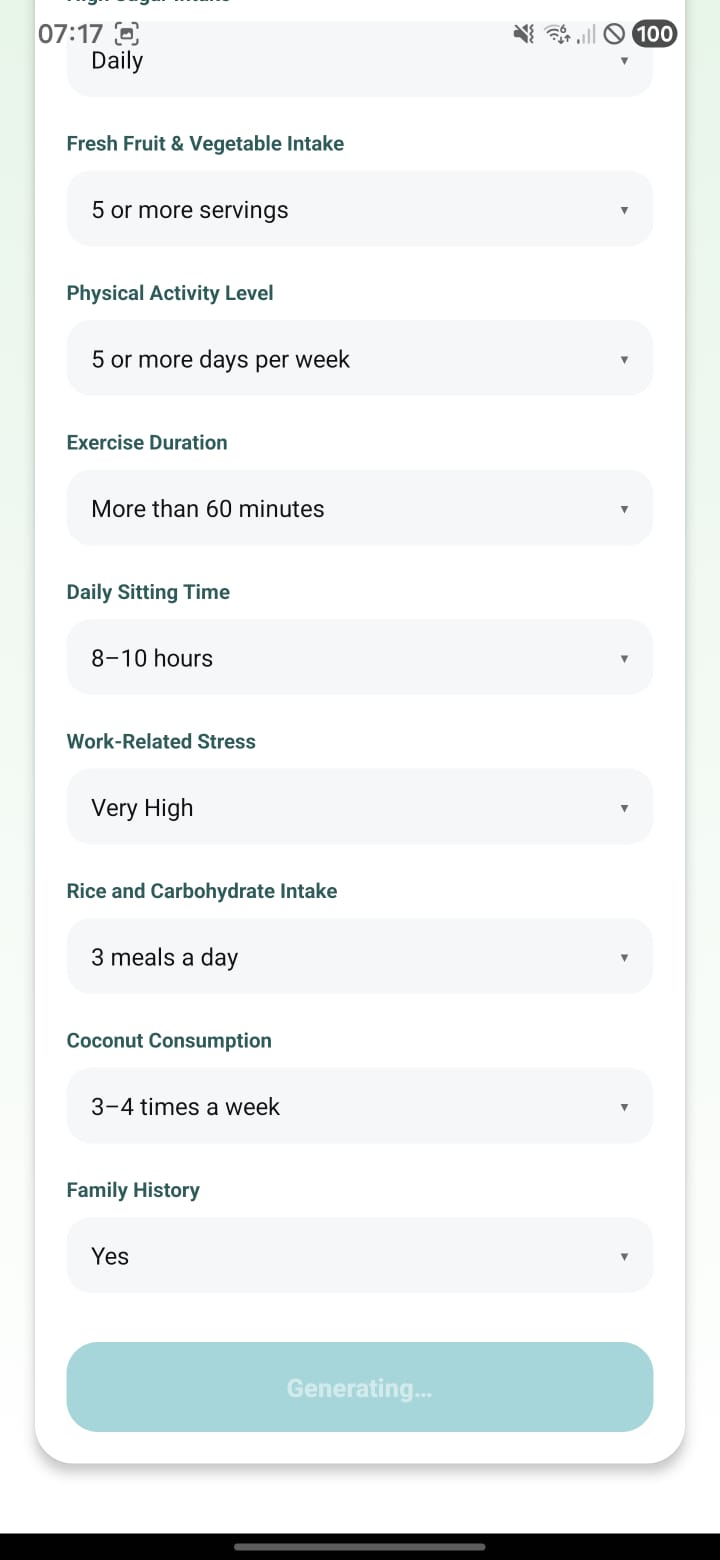
Screen: LifeFactorsFormScreen (bottom half). All dropdowns filled (fresh fruit & vegetables, activity level, duration, sitting time, stress, rice/carb intake, coconut use, family history). The submit button shows “Generating…” while the app waits for /predict to respond.
10. Lifestyle form – blank state
Screen: LifeFactorsFormScreen (top). Title “Tell us about your lifestyle” and empty fields for name (optional), gender, age, weight, height, and lifestyle dropdowns (sleep, smoking, alcohol, fast food, etc.) before the user has entered data.
11. Prediction unavailable error
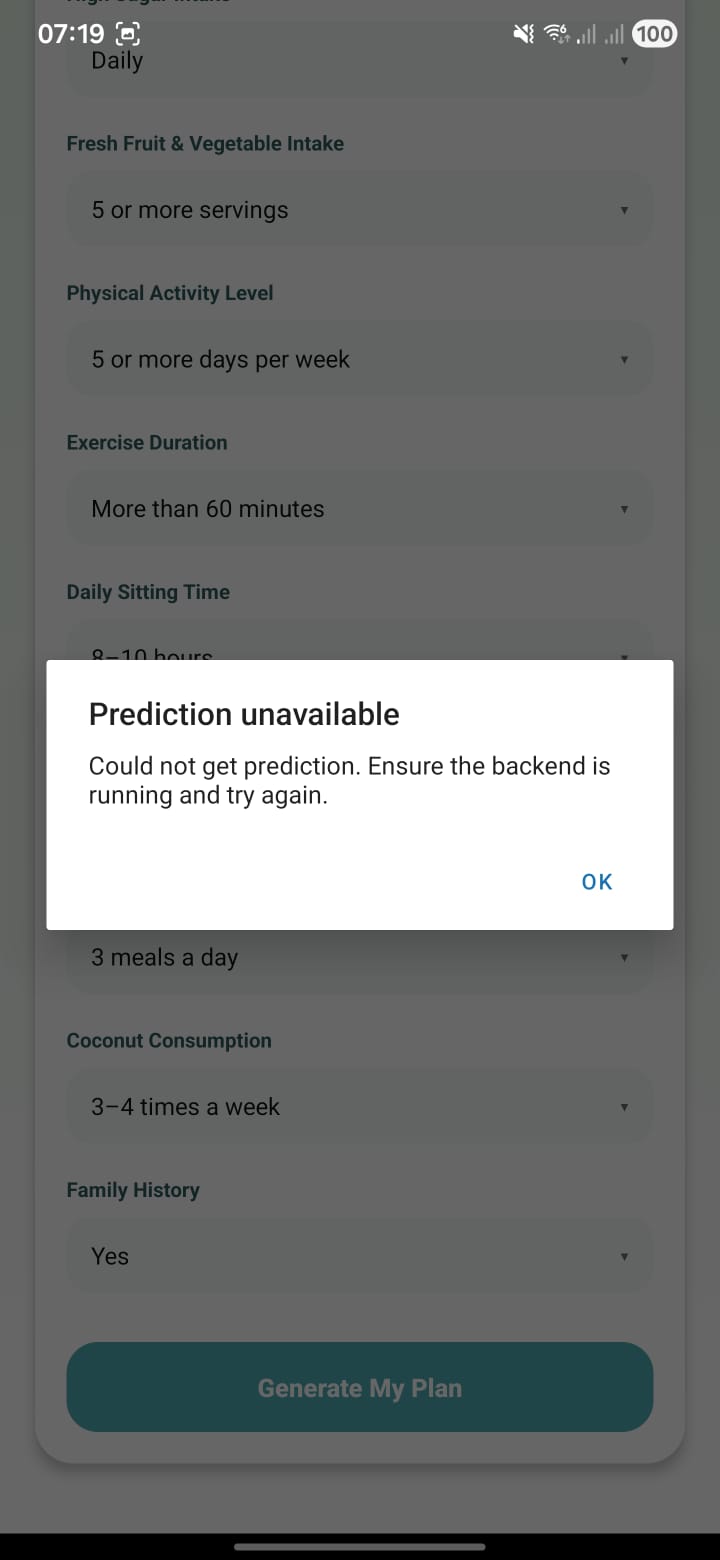
Screen: Error modal on top of the lifestyle form. Message: “Prediction unavailable – Could not get prediction. Ensure the backend is running and try again.” This is what appears when /predict fails (backend down or URL misconfigured).
12. Plan unavailable (503) error
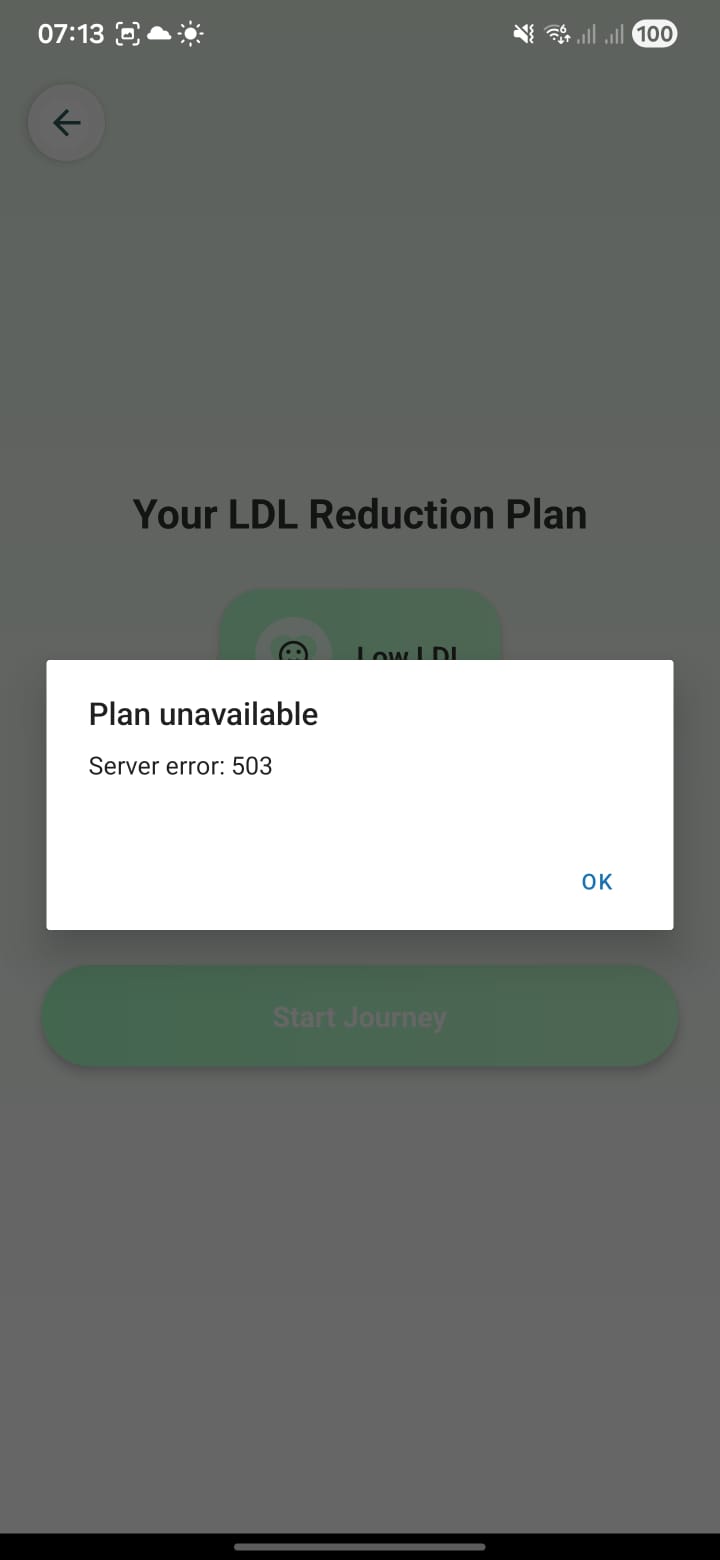
Screen: Error modal on top of “Your LDL Reduction Plan” screen. Message: “Plan unavailable – Server error: 503.” This appears when the guideline LLM endpoint (/guideline) fails or the adapter/model is not loaded.
13. Generating personalized treatment plan
Screen: Loading state after starting the journey. Text: “Generating Your Personalized Treatment Plan – Creating a personalized health plan for you…” with an AI/heart/leaf icon and animated dots while waiting for the guideline JSON from the backend LLM.
7) Project Screenshots (Development)
Terminal output from guideline and chatbot training runs.
1. Guideline model training (Recurv medical dataset)
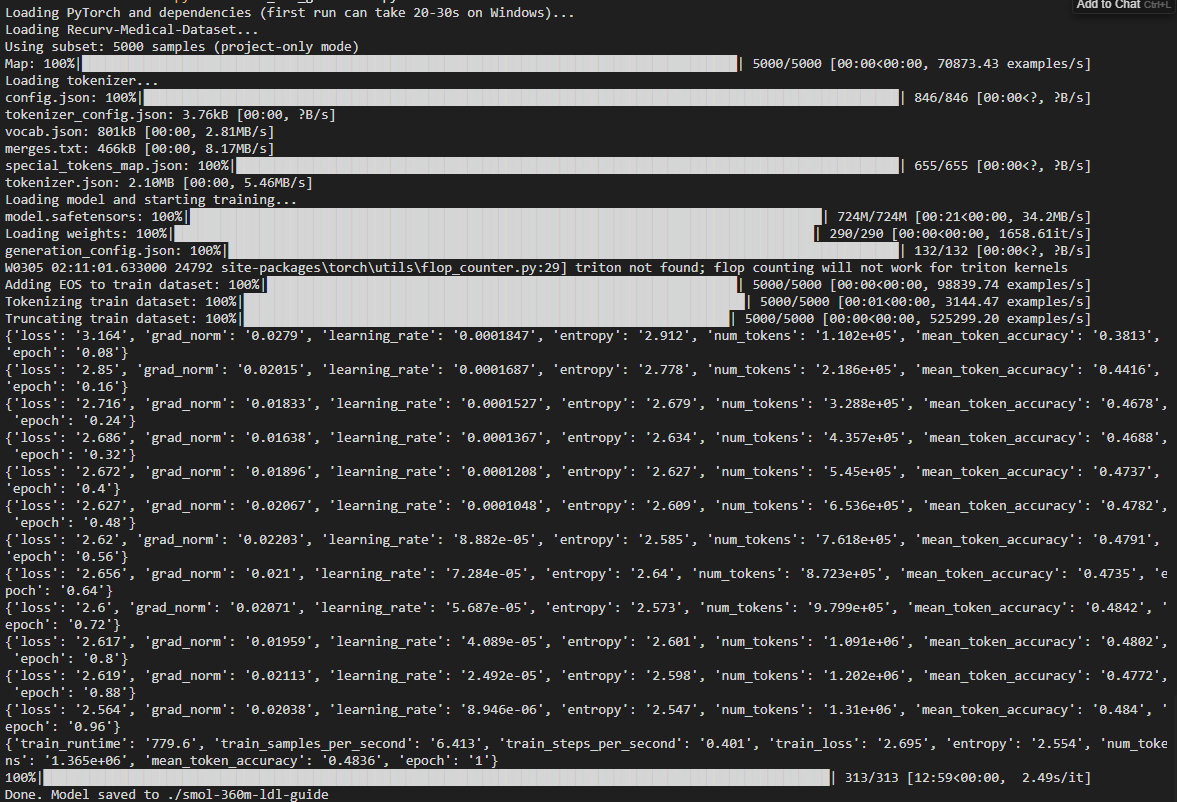
Output from train_ldl_guideline.py: loads Recurv-Medical-Dataset (5000 samples), tokenizer, and SmolLM model (724M). Shows dataset prep (adding EOS, tokenizing, truncating), then one full epoch of training with loss, learning rate, entropy, num_tokens, and mean_token_accuracy. Training took ~12:59 (779.6 s). Final line: "Done. Model saved to ./smol-360m-ldl-guide". There is a Triton-not-found warning (flop counting disabled).
2. Chatbot training – short run (60 samples, 1 epoch)
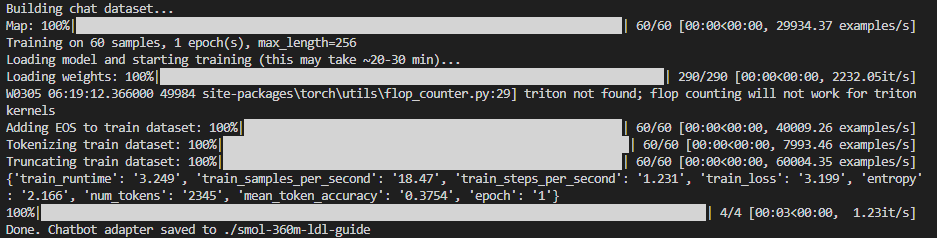
Output from train_chatbot_ldl.py with the original small dataset: "Building chat dataset...", Map 60/60, "Training on 60 samples, 1 epoch(s), max_length=256". After loading weights and preparing the dataset (EOS, tokenize, truncate), training runs 4 steps in ~3.2 s. Summary shows train_loss 3.199, mean_token_accuracy 0.3754. "Done. Chatbot adapter saved to ./smol-360m-ldl-guide". This is the run that finished in about 1 minute because there were only 60 samples.
3. Chatbot training – 400 samples, 10 epochs
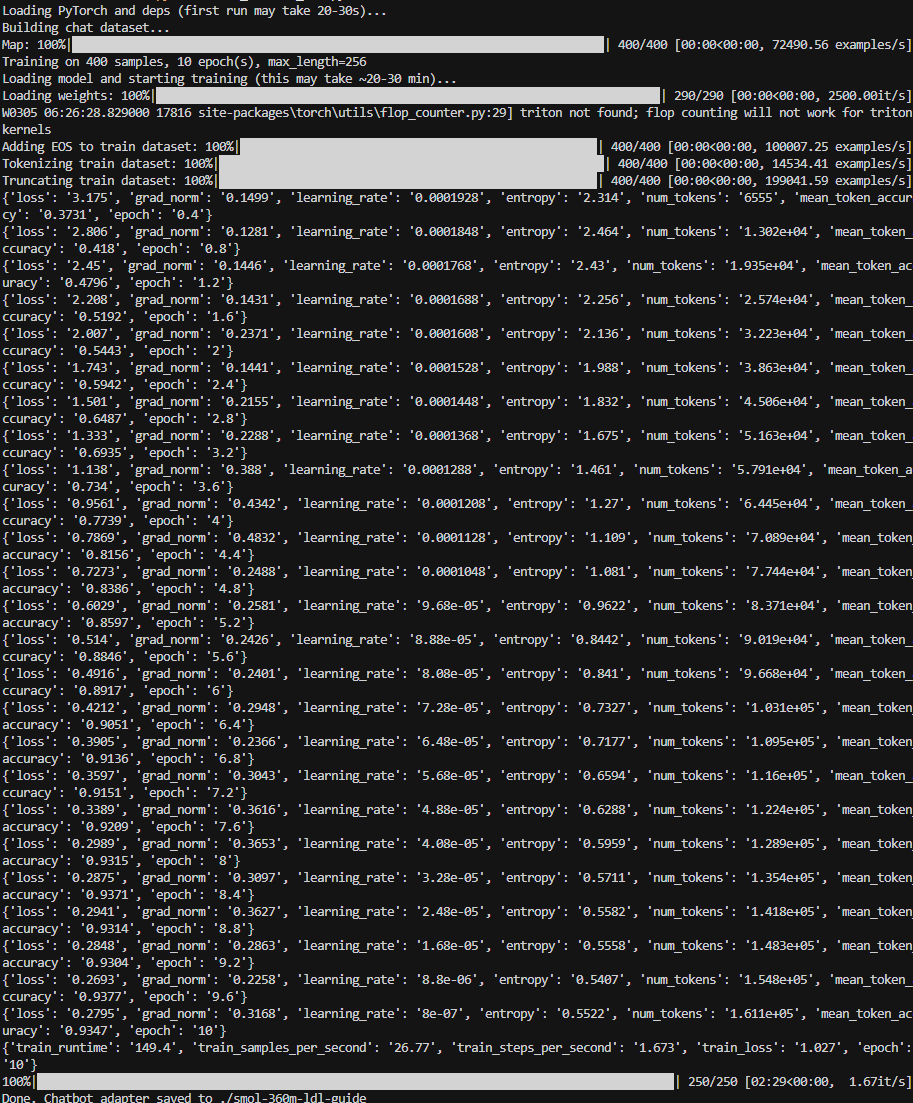
Output from train_chatbot_ldl.py with expanded data: "Training on 400 samples, 10 epoch(s), max_length=256". Dataset mapping and tokenizer load (400/400), then epoch-by-epoch metrics (loss decreasing, mean_token_accuracy increasing) from epoch 0.4 through 10. Total runtime 149.4 s (~2.5 min), 250 steps. Final train_loss 1.027. "Done. Chatbot adapter saved to ./smol-360m-ldl-guide".
4. Chatbot training – long run (15 epochs, 1125 steps)
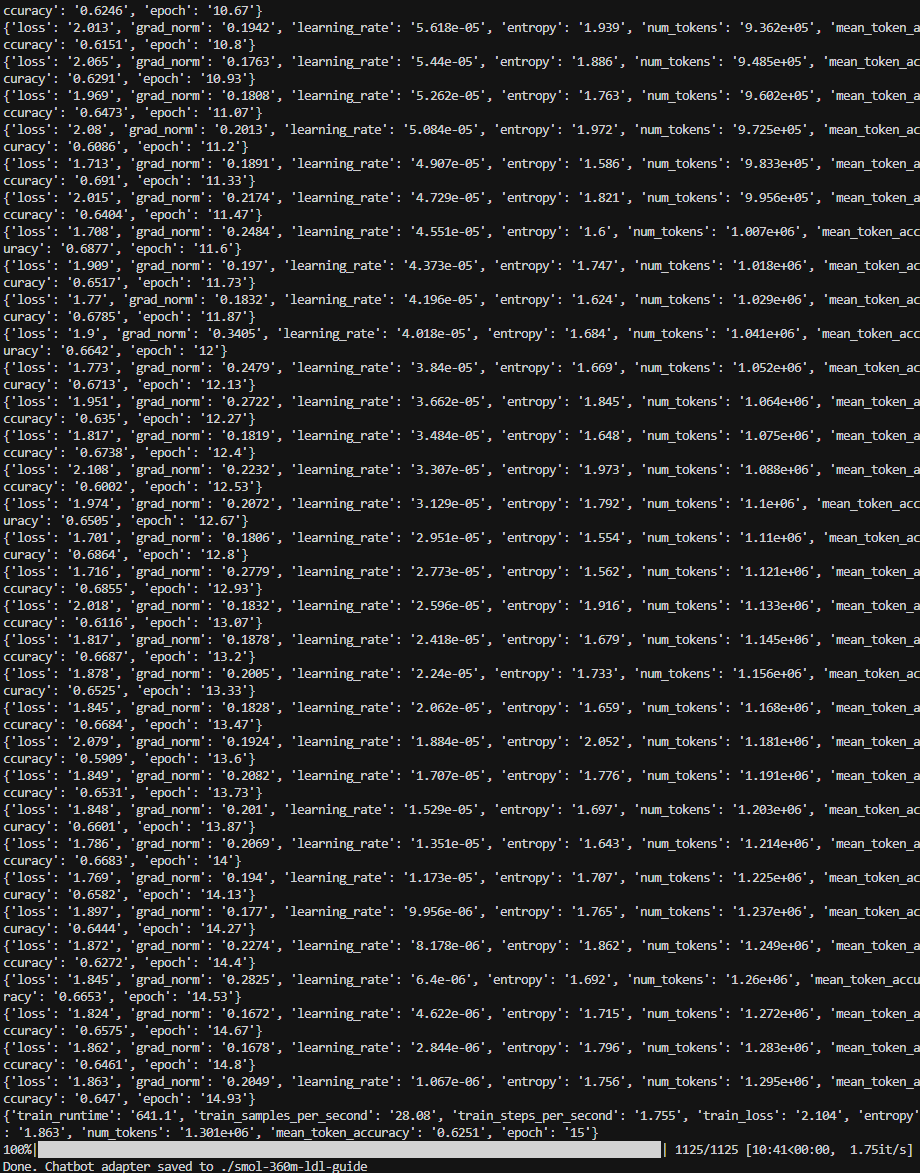
Extended run of train_chatbot_ldl.py: log scroll shows training steps from epoch ~10.67 up to 14.93 with loss, grad_norm, learning_rate, entropy, num_tokens, and mean_token_accuracy. Final summary: train_runtime 641.1 s (~10:41), 1125/1125 steps, train_loss 2.104, mean_token_accuracy 0.6251, epoch 15. "Done. Chatbot adapter saved to ./smol-360m-ldl-guide". This is the longer training with more samples and epochs (e.g. 800 samples, 12–15 epochs).
8) Important Code Parts
API base URL
const DEV_API_URL = process.env.EXPO_PUBLIC_API_URL || 'http://192.168.1.1:8000';
export const API_BASE_URL = __DEV__ ? DEV_API_URL : null;Backend LLM endpoints
@app.post("/guideline")
def api_guideline(req: GuidelineRequest):
data = llm_module.generate_guideline(req.riskLevel, req.topFactors)
if data is None:
raise HTTPException(status_code=503, detail="Guideline LLM unavailable.")
return data
@app.post("/chat")
def api_chat(req: ChatRequest):
reply = llm_module.generate_chat(req.message, req.history)
if reply is None:
raise HTTPException(status_code=503, detail="Chat LLM unavailable.")
return {"reply": reply}